
AI Beyond the Prompt
Real world examples for research, knowledge bases and automation in GTM teams.


This week, Microsoft and Google are holding their developer conferences. These are massive AI-fests where the companies that run our lives show us the version of the future that makes them lots of money. New models! Agents everywhere!1 AR glasses (again)!
And that’s just since Monday. Last Friday OpenAI declared their intent to replace augment most of the world’s developers.
In the SaaS world, the talk at SaaStr and SaaStock last week was that you’re behind and AI is going to take your job. Which is fine because anyone who doesn’t use AI to do literally everything should be fired anyway.
It’s a lot.
Don’t get me wrong. The vision stuff is very cool! The products are pretty cool. The Influencers are directionally right about the future of work.
The problem is that most folks—even sophisticated sales leaders—are still muddling through. You can listen to LeBron dissect a specific type of BOB play, but you probably can’t apply that directly to your next pickup game. There’s a lot of specialized knowledge and decades worth of accumulated skill standing between you and success.2
But that doesn’t mean you can’t push yourself.
Down at the local AI gym, people are mostly sharing ChatGPT prompts and trying to figure out how to actually incorporate AI into day-to-day work in ways that don’t feel completely forced.
I’ve been largely doing that same thing in my actual work (product is a different story3) but lately it’s felt a little limiting—there’s more to AI than just pumping prompts into a chatbot.
So over the past few weeks I’ve really started to push myself and my team to use more AI tools in more ways. AI is strange because you really can’t know what it can do until you actually try. Sometimes it does amazing things. Sometimes it’s godawful.
I’d like to share some of the things I’ve learned4 (good and bad) going beyond basic prompts and how they apply to sales orgs. For some of you this might be old hat, but for others there might be something new you can use for your team.
We’ll look at three different areas: doing research, building a knowledge base, and automation.
Research
This one is the closest to old-fashioned prompting but it’s been incredibly useful for me. I use OpenAI’s Deep Research capability multiple times per week. Google (Gemini), Anthropic (Claude) and others have their own versions of this.
The idea is simple: imagine you could go tell a researcher you want a bespoke report on a topic. Describe what you want and how you want it formatted. They’ll go think about the problem, search the web for a while to find sources and then compile it into something useful.
I’ve found 3 use cases in particular to be extremely valuable: pre-discovery research, market research, and background research for this newsletter. In each case, I can get information in about ~10 minutes (while I do something else) that would have taken hours to compile.
Pre-discovery research
When we go into a prospect call at Gradient Works, we like to have a point of view. That starts with a “why anything hypothesis”—our best-informed guess about why the prospect might want to change their status quo.
For us, the best way to form this hypothesis is to learn as much as possible about how the prospect runs their GTM motion. Getting a real bead on this can take poring over lots of sources. It’s a perfect task for deep research.
Like most AI features, what you ask for matters a lot. I’ve built a pretty comprehensive prompt template for our discovery calls. Honestly, it’s probably overkill but it gives us a thorough look into all the facets of the business we want to understand.
Here’s how to use it:
Replace every instance of {Prospect} with the company name and {WEBSITE} with the company website.
Go to Edit → Select All, then Edit → Copy as Markdown (if you don’t see that option, enable it first).
Paste it into ChatGPT, click the “Deep research” button and go. (Note there’s a limit on these at the different plan levels so don’t go nuts.)
Inevitably it’ll ask you several questions which you can answer as you see fit (you can also just say “Run the report as specified” and it’ll shut up).
It’ll think for while (10+ minutes) and print out updates as it goes. You can go off and do something else.
When it’s done, you’ll have a fully built report which you can read there or export to a pdf.
Here’s an example output for Fivetran. It’s pretty comprehensive but still relatively skim-able.
There’s nothing magical about my prompt, so feel free to grab it and make it your own.
Market research
It’s pretty straightforward to take something like the above prompt and ask it to broaden its research to a small set of companies or an overall industry. A few months back, the team used deep research to help with our GTM Trends in Identity Management report. We started by feeding Market Map cluster data plus a prompt into deep research, but then heavily edited the end product for accuracy, style and presentation.
I’ve also found that deep research is great for developing kill points or doing a SWOT analysis vs a competitor. Ask it to research your company and the competitor and report on relative strengths and weaknesses.
It’s not as good as a real industry analyst or a dedicated PMM, but it’s darn close—and much faster. I highly recommend this as a starting point when selling to a new niche or encountering a new competitor.
Background research
Not everyone writes a newsletter, but there are often topics you want to know more about to help you form an educated opinion. You can ask vanilla ChatGPT about these things but the answers will usually be shallow because it’ll only do a cursory search. If you want to go deeper you could Google for hours, get lost in a YouTube rabbit hole or just use deep research.
I’ve used deep research to estimate the number of SaaS products that exist, survey the sales signals vendor landscape and generate a timeline of sewing machine innovation.
I usually find the reports themselves are helpful but the real interesting part is where they lead you. Go look at the sources themselves or go deeper on specific topics that come up.
Knowledge base
One promise of AI is faster answers to important questions. It should draw from both “world knowledge” and your own proprietary internal information to synthesize the exact answers you need. Who needs specialized knowledge base software for reps? Let’s just use AI!
The reality is a little more complex.
A few months ago, our GTM team set up a Custom GPT in ChatGPT. We uploaded files with customer quotes, case studies, a list of customers with use cases and other collateral. We could then ask it questions like “which customer was using Market Map to target senior living centers?” or “what results has Customer X seen from using dynamic books?” and get pretty good (but not great) answers.
This is, in some ways, better than a lot of commercial knowledge base products. And certainly cheaper.
That said, Custom GPTs have some really frustrating limits:
They’re hard to maintain. You can only provide 20 “knowledge” files and you have to manually upload those one by one.
They make up stuff. It’s very hard to prompt them to only pay attention to the knowledge files and not start guessing.6
Under the hood, they’re fairly limited in how much data they can look at at once (their “context window”) so they sometimes struggle to find the right data to answer questions when the information is spread across multiple sources.
Lately though, I’ve gotten excited about Google’s NotebookLM. Google launched it way back in 2023 as a sort of R&D prototype but has steadily improved it. In fact, they just shipped a NotebookLM app at Google I/O on Tuesday.
The basic idea is to give a “notebook” a set of “sources” (e.g. urls, files, YouTube videos) which it then uses to answer questions about topics covered by the sources. It even lets you create custom podcasts from the content with two very convincing “hosts” having a discussion about a specific topic. (If you’ve heard about NotebookLM before, that was probably this feature that you heard about.) As you can tell from the “notebook” language, it’s more geared towards learning than Custom GPTs.
Custom GPTs and NotebookLM do things slightly differently but both offer the promise of a centralized knowledge base your sales team could use in lieu of specialized products. So which works better?
I decided to put them to the test by creating an Uncharted Territory knowledge base in each. My goal was to be able to ask questions about the articles I’ve published here and get back useful answers.
I’ll go ahead and spoil this: NotebookLM literally made my jaw drop. The Custom GPT mostly sucked.
Just look at this side by side comparison:
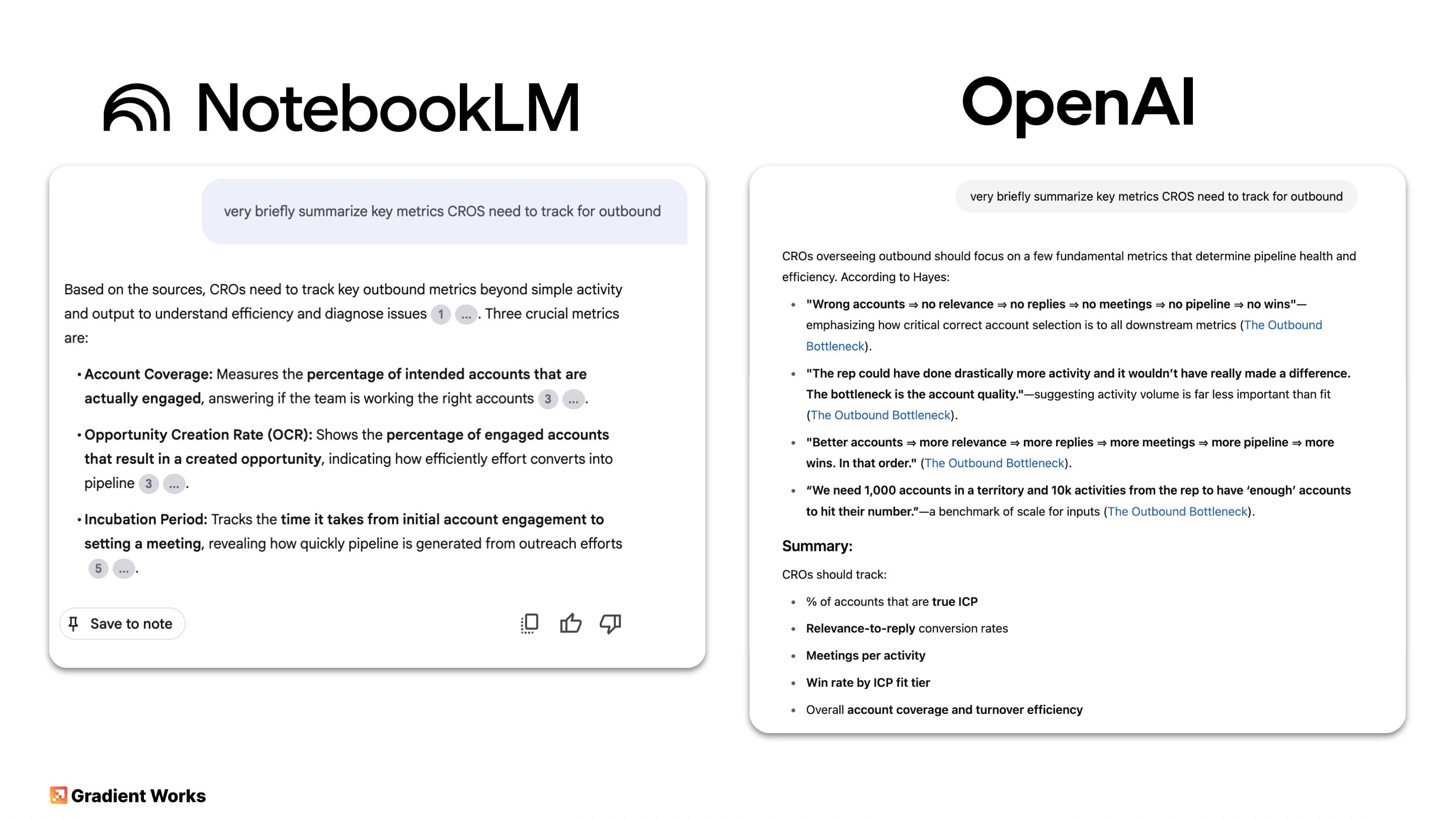
NotebookLM found the 3 Outbound Metrics CROs Need article and correctly summarized the main points—no hallucinations. The Custom GPT found a semi-relevant article, got some real quotes and then made up some summary conclusions.
Unfortunately, this is after I spent quite a bit of time attempting to make my Substack posts conform to the Custom GPT file restrictions and tune the Custom GPT responses. For Notebook LM, I just added links to my posts as well as some of my YouTube videos, and that was it.
Now, to the jaw-dropping part. I used NotebookLM’s “Audio Overview” feature (aka AI Podcast) and prompted it to explain to CROs in the midst of planning season why they might want to consider dynamic books to drive more pipeline. Here’s what it produced:
It’s shockingly good! While they namecheck my Carve Pumpkins, Not Territories post from Q4 of last year, it weaves in content that clearly comes from other posts about territories as well.
It’s not perfect. Sharing is limited to your Google Workspace users, it can still hallucinate (just not very much) and there’s no API.
However, if your team runs on Google Workspace, give it a shot. The stuff above is free. Imagine having this for your core messaging, your ICP docs, your ROE docs, your comp plan, case studies, etc. Beats the hell out of a shared Google Drive.
Automation
I’ll have more to say on this topic in an upcoming article on GTM Engineering, but I wanted to touch on it briefly now. This is more technical than the other two, so if that’s not your jam, feel free to skip to the end of this section for the tl;dr.
Despite building an AI account research agent for the last year, we haven’t used “agents” much internally at Gradient Works. Like a lot of AI terms, “agent” has been stretched to its breaking point. So what actually is an agent?
Believe it or not, the AI computer science course I took back in 2002 using the classic Russell and Norvig book (iykyk) was all about agents. Chapter 2’s first sentence: “An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through effectors.” They describe the goal of an agent as simply “do a good job of acting on their environment.”
Today, you can think of agents as basically an automated workflow that probably uses AI to do some stuff.
Usually that “stuff” resembles Russel and Norvig’s agent: listen for some kind of trigger (sensors), get some data from somewhere (sensors), do something with it (effectors), put some data back somewhere else (effectors), do some other stuff as needed. The magic is that some of the steps an agent takes might not be pre-defined, instead they’re determined by an AI model.
Note that I said some of the steps. An agent typically has some specific steps “programmed” and some left up to AI. The problem is the programming part. Most people can’t program (and/or don’t want to) so ideally building agents should use some kind of “low code” approach.7
This sets up the general requirements for an agent platform:
The ability to get data from lots of places (CRM, Slack, spreadsheets, databases, web pages, etc)
The ability to take pre-defined steps based on the data—including storing data and changing other systems—without having to code
The ability to specify steps and decisions driven by an AI model
The ability to store and communicate results
A lot of tools have sprung up that do this: Zapier (the OG), SmythOS, Gumloop and n8n. Clay is a more specific version of this model centered around data acquisition for GTM teams.8
I recently spent some time building a fairly simple agent with n8n to get some hands-on experience. It was enlightening.
Here’s the basic idea. When I get a new newsletter subscriber, I get a notification email with their email address, their referral source and their Substack profile (if they have one). When I have a moment, I try to look them up on LinkedIn to learn more about their role. It takes a couple minutes because I’ve got to make some educated guesses from their email address about their name and company search for their LinkedIn profile. Wouldn’t it be cool if I could have something read that email and do most of this for me?
The details don’t really matter, but here’s a simple version of that workflow in n8n:
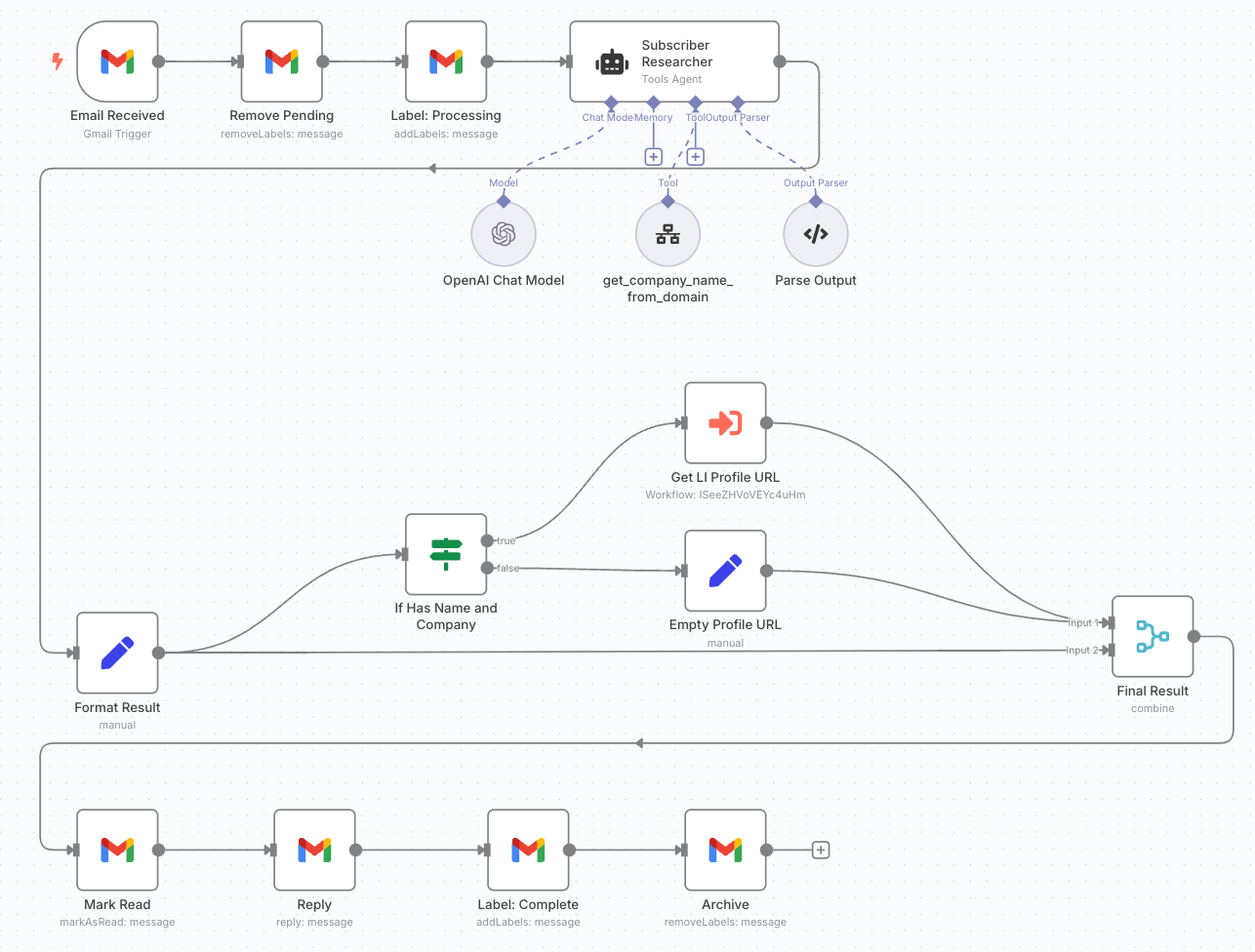
All you need to know is the Gmail logos are steps that read/write from a Gmail inbox, the robot is a small AI agent that figures out the company name from an email domain, and there’s a Google Search to find a LinkedIn profile URL in the middle. It doesn’t go as far as scraping LinkedIn, but I may add that later.
These are roughly the steps I have to do manually. It’s a pretty simple task, but there are 20+ steps that happen under the hood. I could probably push more of it to AI and reduce that further—maybe it could be about half as many “programmed” steps.
In addition to figuring out the workflow itself, I had to deal with security for a special Gmail inbox, OpenAI access, API calls for web scraping, etc. It took some doing.
There’s no shortage of these kinds of tasks in a GTM org. So, there’s enormous potential to increase efficiency with these platforms—most of them have hundreds of different kinds of integrations and action steps as well as access to all the major AI models. These are all building blocks just waiting to be combined into scalable processes. For example, n8n has lots of Salesforce integrations. I could connect this agent to CRM to see if we’ve ever talked to the subscriber in another context.
tl;dr agents are powerful but don’t just appear as soon as you sprinkle some AI fairy dust and say the magic words—they take some work. As I experienced first hand building this very simple example, 3 things become very important in an agentic world:
The ability to clearly define the workflow you want. You need to describe what you want to happen along with the inputs and outputs. Right now you’ve also got to describe most of the steps to take as well. As systems get smarter, maybe it’ll be easier to just say what you want and get it.
Integrations and data. If the data you need is locked away in an inaccessible legacy system or the action you want to take is locked down by infosec, your agents won’t get very far. Be prepared to describe what you need, why you need it and defend it. This is going to be a huge source of tension between security teams and the rest of the business.
Technical creativity. Someone on your team needs to think creatively about how to go from definition to action. They need to know what’s possible, how to work around limitations and how to redesign human workflows into something that can be delivered by an agent—sometimes they need to sew like a machine.
More on the implications of all this in a future post.
Wrapping up
There are some quick wins here for your team, especially with more informed discovery thanks to deep research and new approaches to enablement with NotebookLM. If you’re not doing it today, go give those a try. If someone on your team isn’t thinking about how to build agents, put someone on it. You’ll probably see some immediate impact.
AI moves crazy fast. You probably don’t need to be at the bleeding edge, but it is time to put AI to work beyond the prompt.
Not to mention technical ideas about how to save the entire open web.
Unless you happen to be an NBA player, in which case I’m glad you’re reading and may I please have some tickets?
We’ve been deep into LLMs for a couple years now at Gradient Works, launching Market Map in 2023 and AI Researcher in early 2024.
I will not say “learnings”.
Here it is in plain old markdown format. Click the “Raw” button to get the unformatted text.
This usually means a drag-and-drop way to connect steps together. Or you just describe the agent you want and have AI do the whole thing. You can sort of do that now in some platforms.
Before all the Clay aficionados come after me, I know this is a simplistic description.