
The Bad Data Binary
Living with chronic data disease.


Many of my conversations with GTM leaders hit a wall at “data”. We’re talking about pipeline improvements. They’re getting excited. Then a switch flips in their brain. The energy drops. They trail off. “But we can’t do that because we’ve got such bad data…”
The fact is, I’ve never met a GTM leader who claimed to have “good” data so this happens a lot. It comes in many different flavors:
“We can’t give reps more focused books. Our territories are so big right now because we just don’t know X and reps have to DQ so many accounts…”
“We can’t get connect rates up so we just have to do more activity. We’ve tried all the providers but their phone numbers are terrible…”
“I know we’ve got 50k accounts but we can’t work them. Marketing bought a bunch of lists over the years and there’s tons of old stuff in there plus a lot of duplicates…”
“I can’t stop reps from stepping on each other. Our hierarchies are terrible. Somebody loaded a bunch of data before I got here and nothing’s connected…”
And on it goes.
This deflated conversation happens with both sales and RevOps leaders even though it affects each of them differently. RevOps folks mostly seem tired—a bit worn down by the scope of the problem. Sales leaders are more frustrated. They usually can’t solve the problem directly but they have to live with the consequences.
There’s one more contributing factor to the defeatism. Most companies treat bad data like a sickness. They think: “we just need to take these antibiotics and we’ll be cured.” They tolerate the current situation and make plans for what they’ll do once they’re all better.
The cure never comes, because “bad” data is like a chronic disease. You can’t cure it; you can only manage it. The fact that everyone seems to have the same disease doesn’t make the symptoms any better.
There’s plenty of help out there. Just like in real life, it’s a big business to sell the drugs to manage a widespread chronic disease. Clay just raised $100M on a $3.1B valuation. ZoomInfo pulls down a cool $1.2B in revenue annually1. Yet, the symptoms persist.
Like most chronic diseases, the pills help but they’re not the full solution. You’ve also got to make some changes to your lifestyle and your perspective.
In this article, I want to share a framework that can enable both sales leaders and RevOps leaders manage the chronic disease of “bad” data. Maybe in the process we can let go of the “good” data vs “bad” data binary and learn to make progress no matter what.
Let’s dig in.
A brief story about bad data
When I started as SVP of RevOps for a publicly traded company, the first thing the CFO talked to me about was bad CRM data—specifically duplicate accounts. He was the first, but he wasn’t alone. As I made my rounds to meet the GTM leadership, every person brought it up. I heard the same story from the ops team I inherited.
I quickly learned all this discontent stemmed from a problematic Salesforce merge six years before I set foot in the door. I didn’t cause it, but it was definitely my problem now. It was clear I would get a brief grace period but it wouldn’t be long before the pitchforks came out.
As I thought about how to avoid those pitchforks, I couldn’t shake the feeling that something was just fundamentally wrong with these data discussions. It took me a couple weeks, but I eventually figured it out. Two things:
There was a “good data” or “bad data” binary. We either had “good data” or we didn’t—no in-between. But there’s no such thing as 100% good data. There is no “cure”. Even the most meticulously maintained CRMs are fundamentally just databases that hundreds of people edit directly. Good luck with that. If you treat good vs bad as a binary, you will fail.
Organizational “learned helplessness”. I consistently heard otherwise confident GTM leaders and ops folks just deflate and say “we can’t do that2 until we fix the data”. Eventually everyone would get frustrated waiting on “good data” and either give up or created workarounds that usually made things worse. Just saying “we can’t do that” can’t be the answer—in GTM you fix the plane while flying it.
The thing that saved me from the pitchforks wasn't a big bang "data quality project". It was dropping the idea of “good” vs “bad” and shifting towards continuous improvement. We stopped trying to find a cure and started managing the problem.
We figured out how to measure the most common “bad data” issues and started knocking them out. We quantified missing fields and identified potential duplicates. We built a dashboard to show progress to the org. We showed each issue shrinking. The goal was consistent improvement, not some final “good data” state.
It wasn’t perfect. But, in the end it eliminated the helplessness from my team and in the organization as a whole. The “we can’t do this until the data’s good” mentality went away. By quantifying the problem, we managed it and found a way to make progress.
Seeing how data—both the reality of the issues and the narrative about them—impacted the business has helped me think about data differently.
What we talk about when we talk about data
There are really two major categories of data that matter to B2B sales teams: the external data about your market and the internal data from your own processes.
Here’s how I break it down:
Market data - information about the companies and people you intend to sell to. I’ll break this down further below but this runs the gamut from names, to firmographics/demographics, to strategy nuggets in 10Ks, to phone numbers. Traditionally this is something you purchase from data providers or obtain manually. Increasingly, it’s something AI can help you acquire.
Internal data - the data created by your own internal processes. This is everything from opportunity stage progressions, to forecasts, to rep notes, to activity logging, to call transcripts. Occasionally this intersects with market data—such as learning something important about a company’s financial situation in a call.
The first step is to figure out if you have a market data problem or an internal data problem. For example, if you can’t track how long prospects spend in each stage of the buyer journey, that’s an internal data problem. But if you’re not able to build a target list of ICP-fit accounts or have terrible phone connect rates, those are market data problems.
There are many, many other posts to be written on internal data problems. To avoid this article blossoming into a novella, I’m going to focus on a framework for working through market data issues.
A framework for tackling market data problems
If you’re in B2B SaaS (especially VC-backed) you’re probably targeting a large market. These markets are large in dollar terms and usually in terms of the number of “entities” involved—the companies and people that could purchase your product.
Incidentally, that simple structure forms the foundation of our CRM data. Regardless of CRM, we usually have two pretty primitive types of records to build on: companies (aka accounts) and people (aka contacts).
Markets vary in terms of how easy it is to learn real-world information about those entities and how complex the relationships among those entities are. Understanding the market comprised of small automotive repair shops is different from venture-backed software companies which is different from global hospitality.
In the end though, any B2B CRM’s market data boils down to how it manages those two entities: companies and people. With that in mind, here’s the way I think about categorizing market data issues:

Let’s go category-by-category.
Identity
A chief cause of “bad data” is not being confident that account or contact records actually identify real-life companies and people.
Think about the accounts and contacts in your own CRM. You’ve got accounts someone imported at random from ZoomInfo during an outbound campaign 3 years ago or contacts from that list of trade show attendees you imported in 2019. In each case, you probably only got a couple of pieces of identifying information: usually a name and then maybe a website, an email address or the odd LinkedIn URL.
You’re left with a ton of records like “Acme, LLC” with no website. Or “Weyland-Yutani” with the website www.facebook.com. Or 6 different contacts named “Chad [not provided]” with various gmail addresses.
And don’t get me started on duplicates (the source of my near-pitchforking). Let’s just say that Salesforce’s native duplicate detection leaves a lot to be desired. You can bet that “Acme, Inc” and “Acme Co (New)” have both snuck in over time.
The solution here is a form of “identity resolution”. We need to look at a few data points to see if we think any given record actually represents a particular real-world entity. This used to be the sole domain of data providers but increasingly you can do this with tools like Clay, n8n or Zapier (along with a dash of AI).
Consider trying to determine identity for an account record. You can usually be confident of identity by looking at 3 interconnected things: the account name, the company website and a social profile (e.g. LinkedIn).
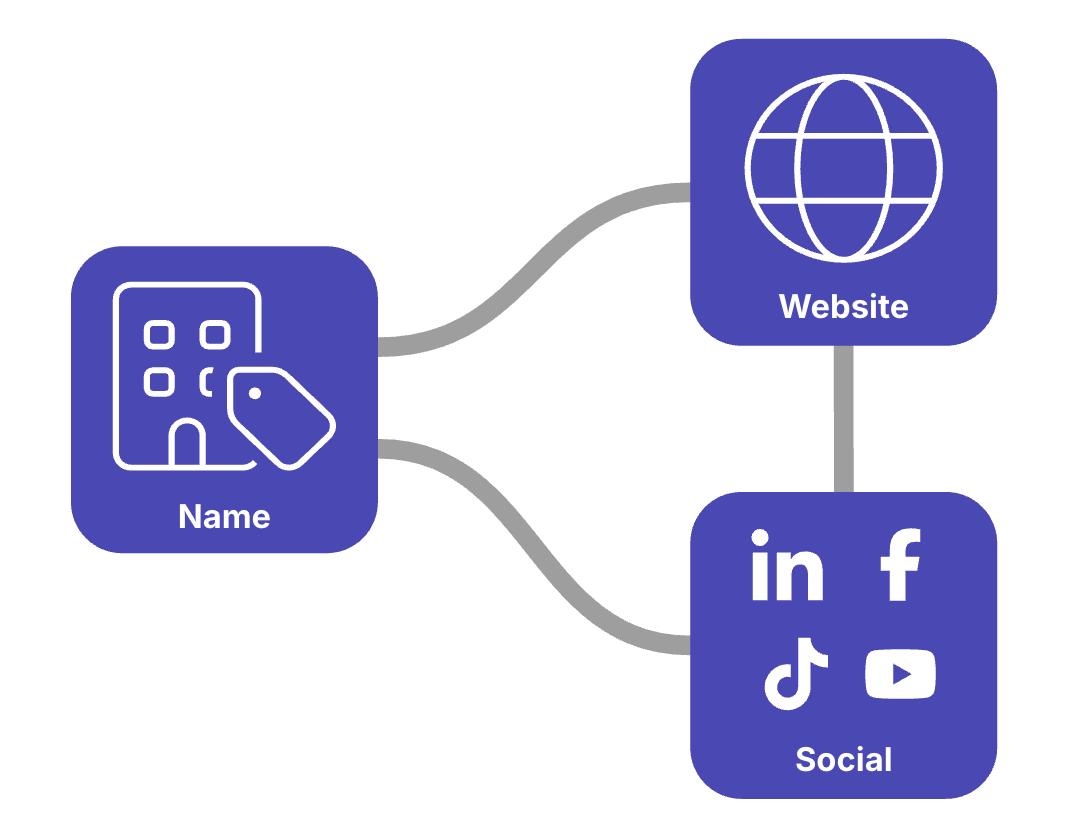
With the right tools, you can:
Validate that a website is active and seems associated with the name
Validate that the website links to a social profile (e.g. LinkedIn)
Validate that the social profile is associated with the name and that the social profile links back to the website
If you’re missing any of these three values, you can also usually find them using modern platforms based on the value(s) you do have.
If all those validations pass, you can be pretty sure you know the real-world identity of the record. You can also learn a lot of other useful information like whether the company has been acquired (the website redirects to another company) or the company is out of business (the website is unavailable).
To start improving identity, you can track how many of your records are missing key identifiers. You can also run a process like the one described above to “resolve” identities and track which ones have issues with mismatched identifiers.
Once you’ve resolved these identities you can then more easily find and merge duplicates. You can also be confident that any additional data points you pursue to enrich those records will be correct.
Completeness
Completeness is simple. If there are manual research tasks your reps have to do because you can’t be sure an account or contact is relevant to the sales process based on what’s in CRM, you likely have too much incomplete data.
Improving completeness starts with a list of all the data points you need to know about a company or person to decide if they’re an ICP or persona fit, respectively. If you’re looking for a place to start, I recommend reading about the 3+1 ICP.
From there you can track “fill rate” for key fields. How many account and contact records have valid3 data for those fields?
This is one of the highest-value places for a GTM Engineer to contribute. Using the right kinds of data providers and scrapers, you can massively increase the completeness of your data.
Connections
When reps are complaining about companies not being included in hierarchies or about contacts being associated with their last role instead of the current one, you’ve got connection problems.
We tend to think about account records as standalone. Contacts are similar with one exception—they’re usually associated with accounts. (More on this in a moment.)
However, no company is an island. They’re connected to other companies. Some companies are subsidiaries of others. Some companies are joint ventures. Some companies are close partners or investors in others.
Lately I’ve been working with a Gradient Works customer that sells software used by hospitality companies. It’s a great example of a complex, interconnected market.
Individual properties (e.g. hotels) may buy software themselves. However, those properties are usually managed by a management company that may make decisions for a group of properties. Sometimes there are separate ownership groups. None of the management companies and ownership groups are household names—most are small and regional. They license the consumer brands we know (e.g. Hilton) from other companies. This interconnectivity matters a lot to the sales process.
People and company relationships also aren’t as simple as the basic account-contact relationship found in many CRMs. People leave roles and join other companies. Some people may hold roles across multiple companies at once. CRMs handle this in various ways with varying degrees of complexity.
Improving connections isn’t as easy as measuring a fill rate. However, this is another place where AI and web scraping can come to the rescue.
It’s often possible to find the connections between companies online. For example, in hospitality, regional management companies usually list their portfolio online. This makes it possible to start to build those connections into your CRM using standard hierarchy functionality.
With people-company relationships, the best source of truth is usually LinkedIn (with all the challenges and limitations that entails).
Accuracy
Low connect rates even though you’ve got phone numbers for all your contacts? High scored accounts that turn out to be much smaller than you realized? You’ve got an accuracy problem.
Whereas completeness is about ensuring you have the all the data points you’re looking for, accuracy is about whether those data points are actually correct.
Improving accuracy isn’t easy. Often the only way to tell that a value is inaccurate is to compare it to another source either manually or through additional enrichment spend.
However, we can tackle accuracy in some meaningful ways. First, we need to look at the two big sources of inaccuracy:
Incorrect data - You’ve just done a big contact enrichment with ZoomInfo. You call the first contact and someone else entirely answers the phone. That’s an incorrect data problem.
Data drift - Most of us can’t afford to continuously re-enrich our entire CRM. Data that was right at the time you enriched it becomes wrong over time. Acme had 1,200 employees in January of 2023 when you last enriched them and that’s what in your CRM. When the rep goes to call in August of 2025, LinkedIn shows 300 after multiple rounds of layoffs.
Incorrect data is the issue we usually think of when we think of accuracy, especially if we’re paying a data provider for the enrichment. It sucks to pay for stuff that’s wrong.
When we all used to contract with a single data provider, we were kind of stuck relying on the accuracy of their data. Things have changed. We now live in a new world where we have “waterfall” enrichments that try multiple data providers, access to myriad speciality data providers that are good in certain regions/verticals, and the ability to run AI agents to seek out up-to-date information on the web. Bad data doesn’t have to be so bad.
Data drift is something you have more control over. With unlimited resources, you could enrich every record in your CRM continuously, but that’s not generally financially viable. Most companies choose to do periodic mass enrichments—usually once a year right before a territory carve.
You can get quite a bit smarter than that. It’s usually possible to run some frequent refreshes on higher-value records that haven’t been enriched in some period of time (e.g. 6 months). This way you can control how much drift you allow for by limiting the amount of time any one record goes without a refresh.
Moving on from the bad vs good binary
You can’t completely eliminate “bad data” which means you’ll never have “good data”. Teams that stop what they’re doing and wait for some future state of “good data” will be frozen in place. There’s no cure, only management.
The only approach that works is to clearly describe the specific problems, measure them consistently, and systemically make improvements. Hopefully this framework will help you on that journey by breaking down your market data challenges into manageable categories of issues around identity, completeness, connections and accuracy.
More about data
A few weeks ago I spoke with Andreas Wernicke as background for my article on GTM Engineering for CROs. If you’re looking for a deeper technical dive into what Andreas calls “foundational data”, this is a great place to start.
ZoomInfo’s current market cap is pretty much equivalent to Clay’s valuation. Not much of a revenue multiple for GTM 0.00%↑ there.
“That” might be roll out a new sales play, improve account scoring, revise territories, change lead routing—just about anything operational you can imagine.
Note that valid here doesn’t necessarily mean accurate. For example in my previous life we had US states in billing addresses represented as full names or abbreviations. We wanted them all to be abbreviations. So a value of “Texas” for Gradient Works may be accurate, but not valid. A value of “London” would be neither valid nor accurate.