
3 Account Scoring Questions
How to decide if that fancy score will do you any good.

This post got a little long so I’ll start with a teaser.
Behold The Uncharted Territory Law of Account Scoring:
The best account score is the one reps actually use so long as it’s better than choosing accounts at random.
Good (or even great) account scores still fail because reps don’t adopt them. They don’t adopt them because the scores sit in the wrong place in the performance vs complexity curve:
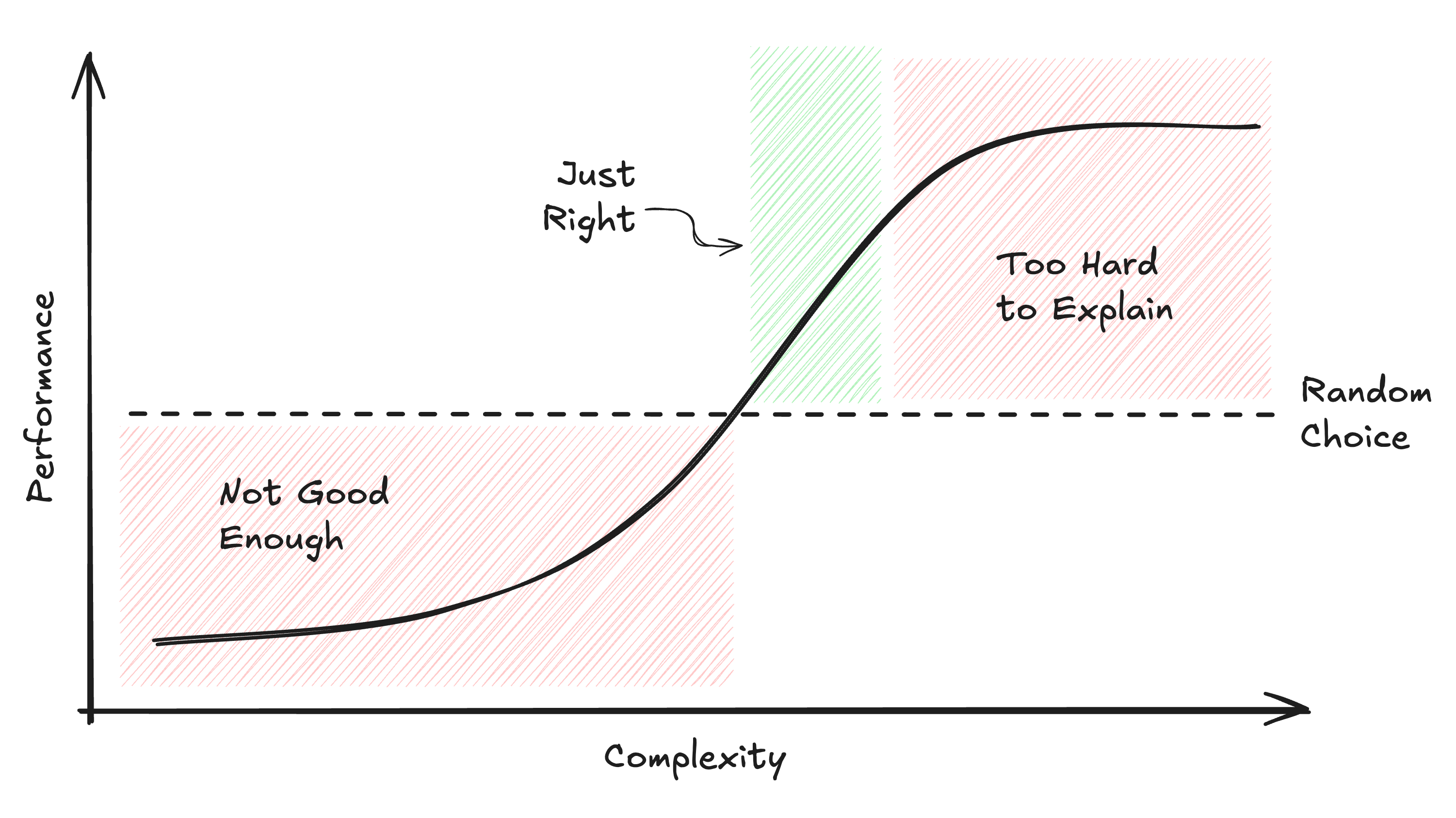
This post isn’t a how-to for creating scores; it’s about helping sales leaders evaluate whether a score produced by your team or a 3rd party will survive in the real world.
Read on. 👇
Let me set the scene. Reps are complaining. Their territories are terrible and the accounts aren’t good. Some reps spend hours researching accounts. Some spray-and-pray. Some just call the names they recognize from LinkedIn. Some are just looking for their next gig.
“Surely we can fix this with some kind of account score,” you think to yourself. So you call up an expert with analytics horsepower—your BI leader, your RevOps leader, your PE sponsor’s operating partner, that high-dollar GTM consulting firm you’ve used in the past—and tell them your woes.
They (hopefully) ask a bunch of questions1 and request a bunch of data. A few weeks later they show up with a shiny new account score. There may also be slides with soothing words and neat charts. Looks great! You put the new score in CRM and tell the reps they can now use it to prioritize their accounts.
A couple weeks pass. You overhear your top rep saying, “I called so-and-so. Tier A. 95/100 in this new score. Completely wrong! They told me to kick rocks. I’m not using this shit.”
A couple months pass. Reps are complaining. Their territories are terrible and the accounts aren’t good…
I’ve seen this many times. In my previous role running RevOps, I inherited a fancy score built using a machine learning (ML) algorithm2. We encouraged the reps to use it when prospecting and we used it to help rank accounts for distribution with dynamic books. Guess what? It was a constant battle because they didn’t trust it.
I learned a lot from that experience. Now, at Gradient Works, we meet a lot of companies struggling with how to prioritize accounts. So lately, I’ve been thinking a lot more about what makes a good account score.
Instead of discussing how to generate a score, I want to share what a revenue leader should know about evaluating a score for the real world. It’s one thing to see an impressive presentation from a data scientist with lots of solid math, but it’s quite another to use their score to actually sell things.
My goal with this article is to help you pressure test a fancy score to see if you can actually use the damn thing. We’ll do it through 3 questions:
What does the score actually tell us?
How can I explain it to my reps?
How will we keep it updated?
Let’s look at what we need to know to properly ask those questions.
Scores, tiers and segments
Let’s step back and remind ourselves what an account score is actually for. Here’s my definition:
The purpose of an account score is to rank accounts based on their estimated value to the business.
I should be able to sort a list of accounts by score and have better accounts at the top and worse accounts at the bottom. If a rep is choosing between calling Account A and Account B, they should feel reasonably confident they should call the one with the higher score first.
Scoring is related to—but not the same as—tiering. Tiering involves bucketing accounts of equivalent quality into larger groups (e.g. Tier A, B, C, etc). This allows us to say that all Tier As are generally better than all Tier Bs. Generally speaking, tiers are built from groups of similarly scored accounts.
Scoring is not segmentation. Segmentation means grouping related accounts together. The most common segmentation is probably company size: SMB, Mid-Market, Enterprise and Strategic. These groups don’t have a relative “rank”—strategic isn’t better than SMB3, it just requires a different sales approach.
Because segments represent very different groups of accounts it may sometimes make sense to have different scoring models for different segments.
So, what’s a scoring model?
Scoring models
When you build an account score, you’ve got to build a “model” that uses historical data to predict something. The “something” you’re trying to predict is ultimately what the score means—and not all “account scores” mean the same thing.
A few examples:
ICP Fit - A higher score implies a prospect is a better fit with your ICP definition. This is (mostly) what we did for our TAL.
Customer Propensity/Lookalike - A higher score indicates a prospect is more likely to become a customer because it shares characteristics with existing customers.
Revenue Potential - A higher score (often denominated in currency) indicates how much revenue the prospect could bring to the business. These can be especially useful in traditional territory and quota capacity planning.
There are many ways to build a scoring model, but they fall into three broad categories:
Rules-Based - These encode intuition or domain expertise into a combo of if/then-style rules and a little basic math (e.g. If Industry = “Manufacturing”, add 5 points). The model is the “formula” that contains the set of rules.
Statistical - If you recall your stats class, you’ll remember things like multivariate linear regressions that use independent variables (e.g. employee count, company age) to predict a dependent variable (e.g. “ARR”). The model this produces is a gnarly equation.
Machine Learning - There are lots of different ML algorithms. Each of them “learn” from training data (e.g. the firmographics of customers) in order to make a prediction about something new (e.g. a new prospect). ML models run the gamut from decades-old algorithms to the neural networks used by modern LLMs. The model is a bunch of interconnected numbers that have been “learned” from the training data. That stuff gets wrapped in a bit of computer code that helps you give it data and get predictions back.
Rules-based models are the easiest to explain to a user, but intuition doesn’t always lead to good performance. In particular, it’s easy to “overfit”—tweaking the rules so much to get them to match existing customers that the model can’t really predict anything but the exact customers you already have. It’s also easy to just add rules because they “sound right” without really validating whether they lead to better predictions.
At the other end of the spectrum are ML models. They attempt to “learn” complex interactions across many data points to produce the best possible prediction. As a side effect, it’s hard to understand exactly why a model makes any given prediction. There are tools for this but they’re not very helpful to normal people.
ML models need quite a bit of high-quality training data. If you only have 100s customers to train the model, it’s tough to get good results. You also can’t just throw in every random data point related to a customer. In fact, figuring out exactly what training inputs to use is its own specialization.
Statistical models don’t add much to our story here. They’re basically more mathematically rigid ML models—similarly hard to explain and less powerful.
Another problem with ML and statistical models is they start to “drift” over time. Updating their predictions usually means periodically retraining the whole thing. The longer you wait, the more out of sync the model gets from reality.
This sounds painful. Can’t you rub some AI on it and have it just magically work?
AI isn’t the (whole) answer
AI can improve scoring in a few ways, but it won’t magically produce a good score.
You can use it to help you derive inputs for your scoring model by, say, scraping otherwise unavailable firmographic data points from the web.
You can use it to build novel models like Market Map that convert account-level market research into deep industry clusters and customer lookalike scores.
You can use it to train your own scoring model. You could plausibly vibe code your way to a decent ML model built against your own data.
What you can’t do, however, is just throw accounts into ChatGPT and ask it for an account score (even if you tell it about your ICP). Sure, it’ll confidently provide you a score, but you should be skeptical.
ChatGPT might actually do ok in some scenarios—e.g. a small list of Fortune 500 companies—but don’t be fooled. The more data you want to process and the farther you get into the long tail of niche industries and private companies, the more it’ll be making guesses. It also won’t be truly learning from your data like a purpose-built scoring model.
In short, use AI for data acquisition with a tool like Clay, n8n or our AI Researcher. Then use one of the methods described above to actually build a scoring model. If someone tells you they’re doing otherwise, be skeptical.
The Uncharted Territory Law of Account Scoring
After all that background, let me share some hard-won knowledge from my experience working with revenue teams, leading RevOps and working as a semi-pro data scientist.
I present to you The Uncharted Territory Law of Account Scoring:
The best account score is the one reps actually use so long as it’s better than choosing accounts at random.
Let’s start with the second part first. That sounds like a really low bar. And it is! I’ll amend it slightly by saying “it’s better than what you’re doing today”. You may have a truly fantastic scoring model today. But if you do, I’m not sure why you’re still reading. For the rest of you, what you’re doing today is probably just a little better than random. Let me explain.
Ok, your reps aren’t actually choosing accounts at random from your entire CRM and calling them. Even in the absence of a score, you’ve likely put ICP guardrails in place (e.g. we’re only working accounts > 100 employees or in industries X, Y and Z). For most of us—especially in commercial sales—that still leaves a large account pool.
Let’s assume our reps are working from the right account pool. But look across a decent sized sales team and you’ll see that engagement with that pool is pretty random. For every rep that’s really focused on researching super-high-fit accounts, another rep is just calling anyone with a pulse and another rep just hitting up well-known names. The net effect is that your team is probably pursuing accounts with a strategy that’s slightly better than blindly reaching into a jar of M&Ms and pulling out a red one.
Now, about that first part.
Like money, an account score only has value if your reps believe in it and act accordingly. Once reps lose confidence, all the statistical rigor in the world won’t save you. And it’s super easy for them to lose confidence.
No account score is perfect. These are models of the real world—not the real thing. Even if it’s spot-on 95% of the time (and it probably won’t be), that means 50 duds for every 1,000 accounts engaged. There’s a 100% chance reps will encounter examples where the score (good or bad) doesn’t match their experience. Unfortunately, the human brain remembers exceptional things. This means the bad accounts will occupy way more attention than they deserve (statistically speaking).
All it takes is an influential rep having a couple bad experiences with high-scoring accounts (or even quick wins with low-scoring accounts) before a little skepticism metastasizes into complete dismissal. When that happens, you might as well have no score at all.
Let’s review. Bad experiences are guaranteed. And bad experiences lead to reps abandoning the score. We’re doomed, right? Not if we design for forgiveness.
Reps can forgive a bad score4, but only if two things are true:
They can understand why the score was wrong
They believe the mistake can and will be corrected
So, the best way to get reps to accept a score is to make it easy to understand, transparent in how it works and simple to update with new information.
Unfortunately, that sometimes conflicts with making the score as accurate as possible (in a mathematical sense). An intuitive rules-based score may not be as accurate, but a complex score generated by the world’s best machine learning algorithm may be a completely inexplicable black box.
Further, the more complex ML-driven scores are often the hardest to adjust and maintain due to retraining. Rules-based scores are much more flexible.
Picking a scoring approach is a bit of art and science that involves a complexity and performance tradeoff that looks something like this:
In summary, a decent, explainable, tweak-able score almost always beats a high-performing black box.
Finally, those questions
So, you’re listening to an expensive consultant tell you about your new account score. Here are the three questions to ask to see if an otherwise well-performing model can survive in the real world:
What does the score actually tell us?
How can I explain it to my reps?
How will we keep it updated?
Let’s look at each in a little more detail.
What does the score actually tell us?
This one should be easy. Are we predicting ICP fit, revenue potential, customer similarity, or something else? Hopefully they’ll have made this clear and you won’t even have to ask it. If they can’t answer this easily, something’s up.
How can I explain it to my reps?
We’re assuming the presenter has shown tests and evaluations that indicate the model works as advertised. We’re not trying to question whether the model works—we’re questioning if we can explain how it works in order to be forgiven when the model is inevitably wrong.
Acknowledge that you understand the model is solid overall but you know reps will have questions. Ask them to walk you through how to explain the choices the model made for a given account.
If they can’t do that, then you need to think carefully about your complexity vs performance tradeoff. Is the model so good you’re willing to risk reps not adopting it?
How will we keep it updated?
If they’re just offering you a one-time list of scored accounts, that’s big red flag. It means you can’t score any new accounts and any adjustment requires an expensive trip right back to them.
If they’re offering you the model itself, that means you can score new accounts. Great! However, if it’s an ML model, you’ll also need the exact instructions to retrain it or you’ll never be able to update it in the future. If it’s a rules-based model, you’ll need documentation on how the rules are applied.
Finally, you need to make sure your team can and will actually be able to manage keeping the model updated.
Wrapping up
Beware the fancy black box score that promises everything but reveals nothing. It may be great, but reps will refuse to forgive it the first time it lets them down (and it will let them down). A score that no one uses is worse than no score at all because you’ve wasted time, money and credibility with nothing to show for it.
Aim for an explainable account score that sits in the sweet spot of the complexity and performance tradeoff. A score like that can have a tremendous impact on your team because they’ll actually use it. It’ll lead to better books, more focus and more pipeline.
Depending on who it is, they may also ask you for a bunch of money.
It used a “rules-based” decision tree algorithm called Cubist. At the time it was built, that was pretty state of the art. There were… problems… in the implementation, though.
Of course don’t tell that to a Strat rep. Yes, each individual Strategic account would likely generate more revenue than an SMB account. However, it’s entirely plausible that the SMB segment could generate way more revenue than the Strategic segment—or vice versa.
Incidentally this is probably true of forgiveness with people. If you can understand why someone made a choice you disagreed with and you can understand that they’re correcting their behavior, you’ll probably be ok.